容器技术正在如狂风暴雨般地改变基础设施领域。虽然容器解决和简化了基础设施管理流程,但是它们在编排方面也引入了很大的复杂性。 那就是Kubernetes想要帮我们解决的问题。 就像指挥一个管弦乐队一样,Kubernetes监控了我们的容器集合——自动启动,停止,创建和销毁它们,以保持我们的应用程序一直处于我们期望的状态。
Kubernetes通过创建多层的抽象,如pod和服务,更容易地管理容器化基础架构。 我们不再需要担心应用程序是否正在运行,或者是否有足够的资源正常工作。 但这并不改变这样一个事实:为了确保良好的性能,我们需要监控我们的应用程序、运行这些程序的容器还有Kubernetes本身。
重新考虑Kubernetes领域的监控
正如容器技术完全改变了我们之前考虑的如何在虚拟机上运行服务一样,Kubernetes改变了我们与容器交互的方式。 好消息是,通过适当的监控,Kubernetes固有的抽象级别可以全面了解您的基础设施,即使容器和应用程序在不断被调度在不同的机器上。 但是,Kubernetes中的监控需要我们重新思考和重新定位我们的策略,因为它与监视传统主机(如VM或物理机器)有几种不同。
Tags和labels变得至关重要
随着容器和它们的编排完全由Kubernetes管理,标签现在是我们与Pod和容器进行交互的唯一方式。 这就是为什么它们对于监控来说是至关重要的,因为所有的指标和事件都将在基础设施的不同层面上(译者注:不同层面可以理解为是Pod Level Service Level)使用标签进行过滤。 使用逻辑和易于理解的模式定义标签是至关重要的,因此您的指标将尽可能有用。
现在监控中有越来越多的组件
在传统的以主机为中心的基础设施中,我们仅监控两个层次:应用程序和运行它们的主机。 现在中间的容器和Kubernetes本身需要监控,所以有四个不同的组件来监视和收集指标。如图1所示。
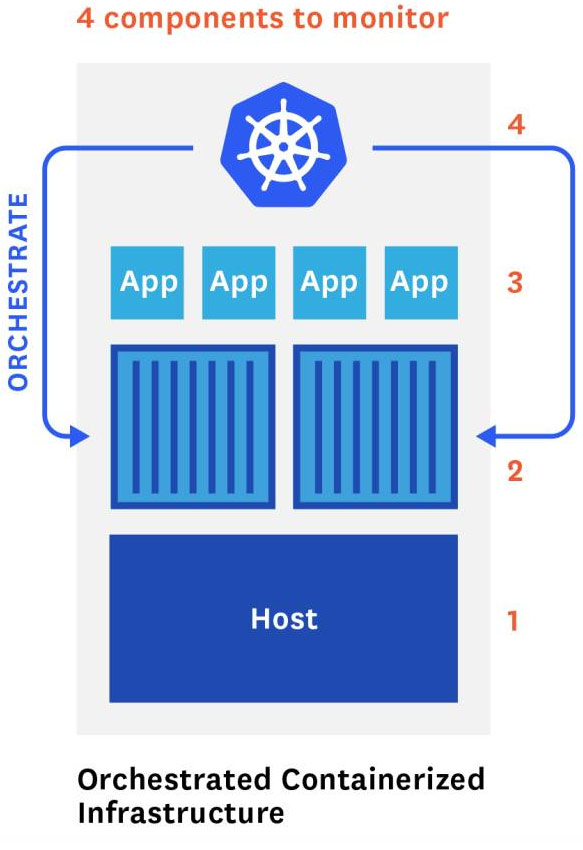
图 1 4-level监控指标
应用程序正在不断移动
Kubernetes根据调度策略动态调度应用程序,因此并不是总能知道应用程序正在运行在哪台主机上。但是他们仍然需要被监控。 这就是为什么必须使用具有服务发现的监控系统或工具。 它将自适应地在移动的容器中收集监控指标,从而可以不间断地持续监控应用程序。
为分布式集群做准备
Kubernetes能够跨多个数据中心和云提供商分发集装箱化应用程序。 这意味着必须在所有这些不同的来源之间收集和汇总指标。
对于这些新的监控挑战以及如何克服这些问题,作者最近发布了一个深入的Kubernetes监控指南。 该系列的第1部分(https://www.datadoghq.com/blog/monitoring-kubernetes-era/)介绍
如何使监控策略适应Kubernetes。
监控指标
无论使用Heapster数据还是与Kubernetes及其不同API集成的监控工具,都需要密切跟踪几种关键类型的指标:
– 运行的pod及它们的部署
– 通常的资源指标,如CPU,内存使用量和磁盘I / O
– 容器的原生监控指标
– 应用程序监控指标。这些指标可以通过监控工具中的服务发现功能来实现
所有这些指标应该使用Kubernetes标签进行聚合,并与来自Kubernetes和容器技术的事件相关联。
作者在指南的第二部分中引导用户去了解需要收集和跟踪的所有数据。
收集这些指标
无论您是希望通过组合Heapster,存储后端和图形工具,还是通过将监控工具与基础设施的不同组件集成到Kubernetes指标集合中来跟踪这些关键性能指标,指南的第三部分都涵盖了。
总结
使用Kubernetes大大简化了集装箱管理。 但它需要我们在几个方面重新考虑我们的监控策略,并确保来自不同组件的所有关键指标得到适当的收集,汇总和跟踪。 我们希望这个监控指南将帮助您有效监控您的Kubernetes群集。 欢迎提出反馈和建议。
原作者
——Jean-Mathieu Saponaro, Research & Analytics Engineer, Datadog

评论前必须登录!
注册